- 1.Google didn’t change the rules. It started enforcing them
- 2.Self-promotional listicles without real testing got hit hardest
- 3.Superficial “2026 updates” (just changing the year) no longer work
- 4.AI still favors comparison content, but only if it’s credible
- 5.What works now: real testing, clear structure, measurable data, and transparency
In January 2026, a content strategy that had worked for hundreds of SaaS companies suddenly stopped working. Overnight.
In February, Lily Ray published research that made the entire SEO community take notice. She'd been investigating Google's January volatility (the unexplained ranking chaos that followed the December 2025 Core Update) and started sharing traffic drop examples that were hard to ignore. Company after company, the same pattern: 30% to 50% visibility losses within weeks.
And these weren't site-wide penalties. The drops were targeted, concentrated specifically in blog subfolders, guide sections, and tutorial pages. Exactly where companies had published their "Best [Product] in 2026" comparison content.
You've seen this type of content everywhere. Search for almost any software category and AI Overviews pull directly from these listicles, ranking tools, surfacing brand names, citing the articles as sources.
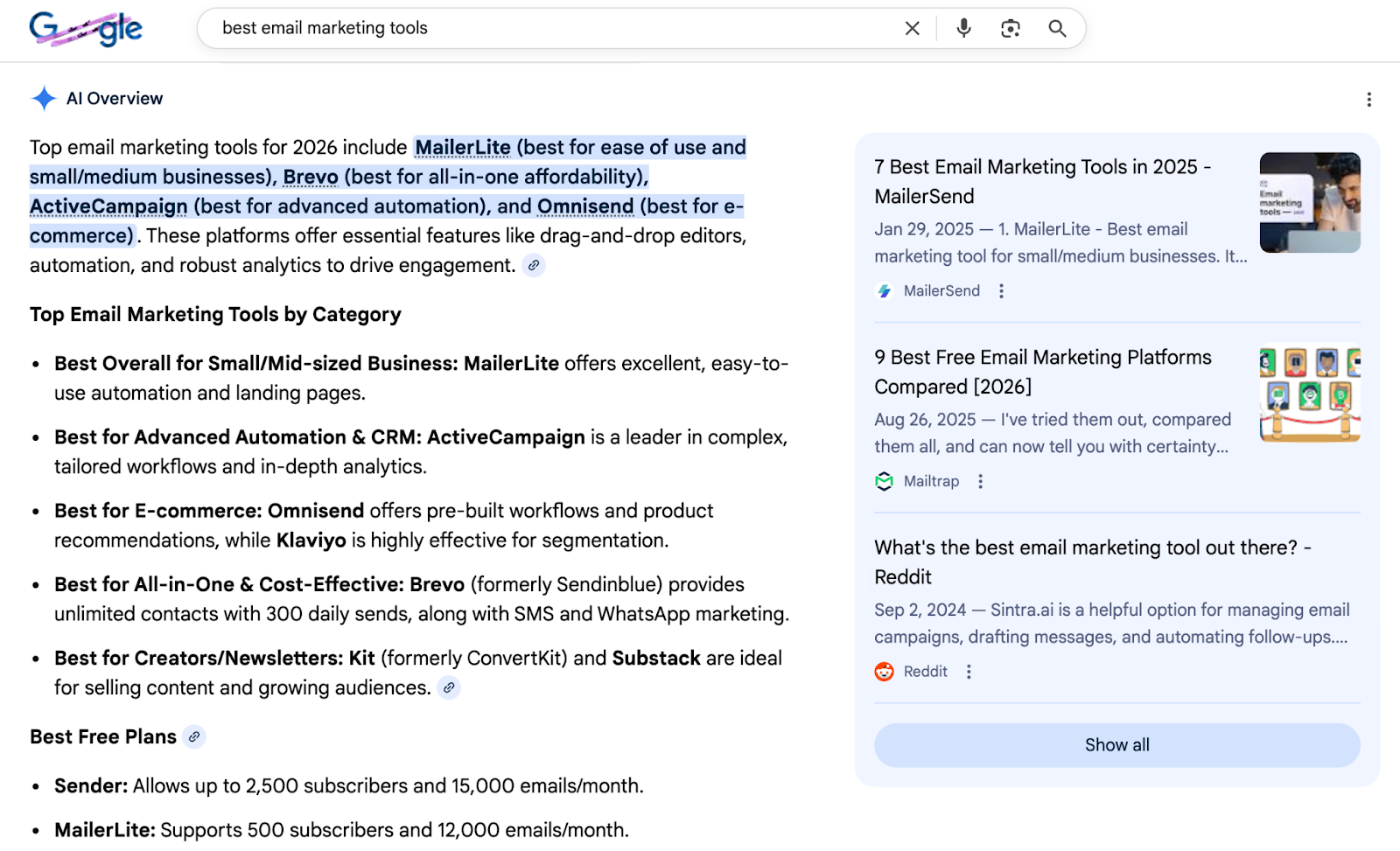
These were established SaaS brands with experienced marketing teams, following what looked like industry best practices. Most trusted sources said listicles dominated AI citations. The guides said keep it fresh and structured. Everyone was doing it.
So why did it backfire?
That's what I'm going to cover today: what actually happened, why it was more predictable than it seemed, and what actually works in 2026.
The 2025 listicle rush: why everyone was doing it
To understand why so many sites got hit, you need to understand the context of 2025.
Throughout the year, if you were trying to figure out how to show up in AI-generated answers, every guide pointed toward the same strategy: publish comparison listicles.
And this wasn't just random advice. The data backed it up.
In December 2025, Ahrefs researcher Glen Allsopp published a study analyzing ChatGPT responses across 750 prompts in three categories: software, products, and agency recommendations.
Blog lists were the most cited page type across every category, 43.83% on average. For software queries specifically, the number jumped to 51.39%. The next closest page type? Landing pages at 14.6%. Blog posts at 6.72%. Everything else was a rounding error by comparison.
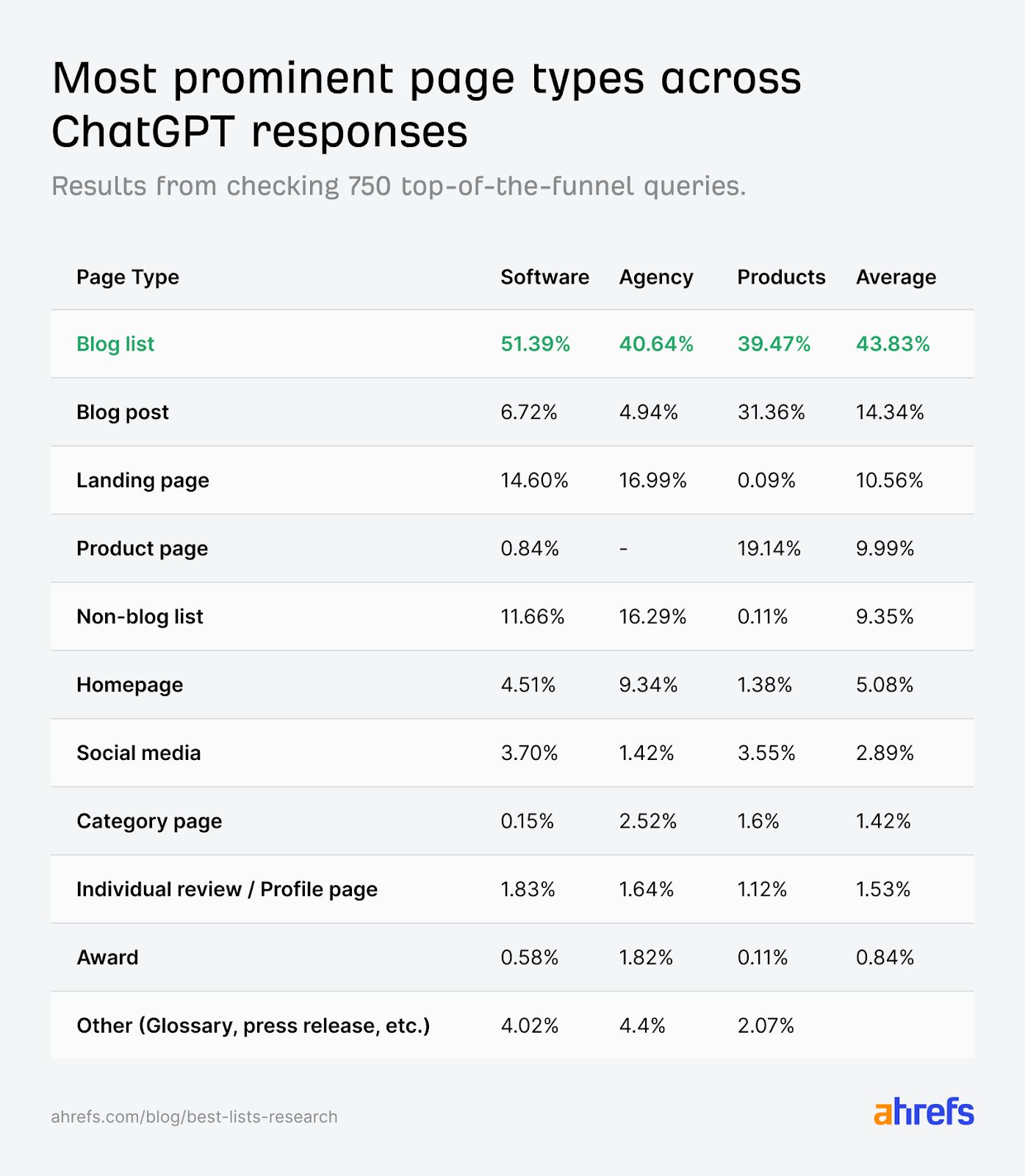
The study even noted that self-promotional lists (where brands ranked themselves first) were among those being cited.
Also, Exploding Topics and Search Engine Land published guides throughout 2025 explaining how to optimize for AI citations. The advice was consistent: structure your content as comparisons, keep it fresh with current year markers, make it easy for AI to extract and quote.
So companies followed the playbook.
They published articles titled "10 Best [Service] Companies in 2026" and ranked themselves at position #1. They updated titles with the current year because everyone knew AI systems favored recent content: queries like "best accounting software" would trigger AI to look for "2026" results specifically.
And here's where it gets interesting: collaboration became common. Companies started mentioning each other in their respective listicles. The goal was: You rank us in your "Best Marketing Tools" article, we'll rank you in ours.
For a while, it worked. Sites saw traffic increases. Brands appeared in AI-generated answers. The strategy seemed validated by results.
Nobody was hiding this approach. It was documented in case studies, shared in LinkedIn posts, taught in webinars. Industry data supported it. Credible sources recommended it.
Then the Google crackdown hit: what actually happened
In January 2026, a shift happened.
Barry Schwartz at Search Engine Roundtable reported significant Google ranking volatility just a couple weeks after the December 2025 Core Update was completed.
The ranking fluctuations were widespread enough that SEO professionals knew something was happening.
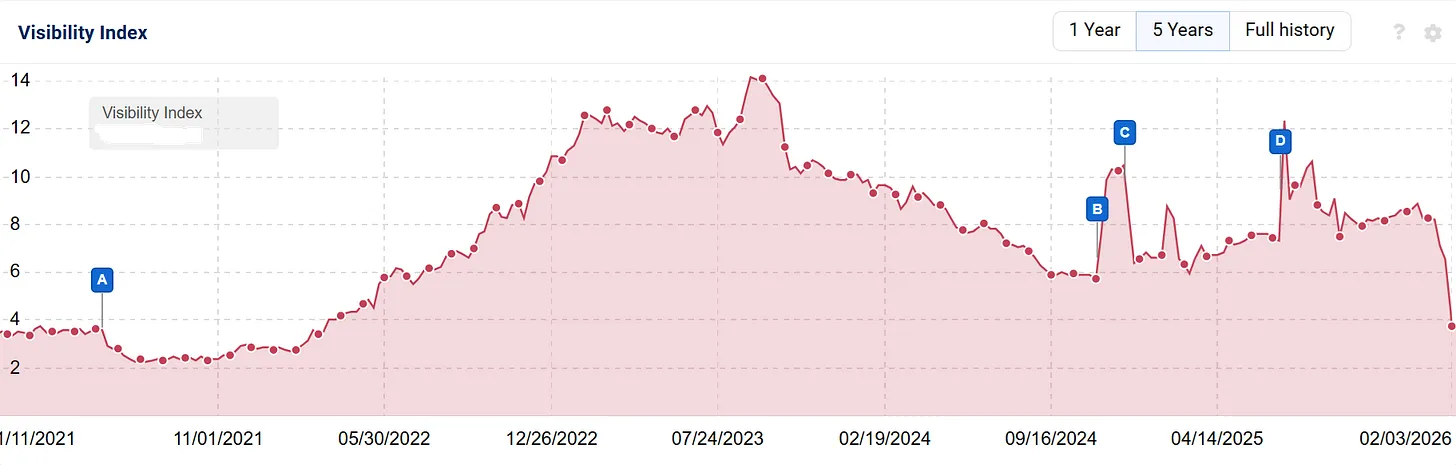
That's when Lily Ray started investigating. She looked at sites experiencing steep visibility declines and found a pattern that was too consistent to ignore. These sites shared a common content strategy: they had published dozens or even hundreds of self-promotional listicles, ranking themselves as the #1 solution in their category.
The visibility drops were concentrated in specific areas. Not homepage rankings. Not product pages. The hits were specific, targeting blog subfolders, resource sections, and comparison guides. Exactly where companies had built their listicle strategies.
Many of these articles had been "updated" for 2026. But when you looked closely, the updates were superficial. Companies had changed "2025" to "2026" in the title and adjusted the text. But nothing had actually been retested. The products were the same, the comparisons were the same, only the year in the title was different.
The articles lacked the evidence Google's review guidelines require:
- No screenshots showing hands-on product testing
- No documentation of when testing occurred
- No methodology explaining the evaluation criteria
- No quantitative data comparing performance
- No transparent disclosure about the publisher's own product being ranked #1
Some sites saw 30% drops. Others lost 50% of their visibility. And because the losses were concentrated in content hubs that had been driving significant traffic, the business impact was immediate.
Why this was always risky (Google's warnings were there)
Here's what a lot of people missed: Google had been warning about exactly this type of content since 2021.
That year, Google launched its product reviews system specifically to address low-quality review content.
Comparison articles that summarized products without evidence of actual testing, independent evaluation, or first-hand experience. Over time, this system was folded into Google's core ranking algorithms. The standards never went away. They just became part of how Google evaluates everything.
Here's where self-promotional listicles walked into a trap.
When a SaaS company publishes "Best CRM Tools 2026" and ranks themselves #1, Google's system doesn't read that as a blog post. It reads it as a review. And review content is held to a specific standard. Google's new write high quality reviews guidelines require:
- Evidence from having actually used the product
- Original photos and demonstrations showing the product in use
- Quantitative measurements of how products perform
- Explanation of what sets products apart from competitors
- Discussion of benefits and drawbacks based on research
- Clear methodology showing how products were tested and compared
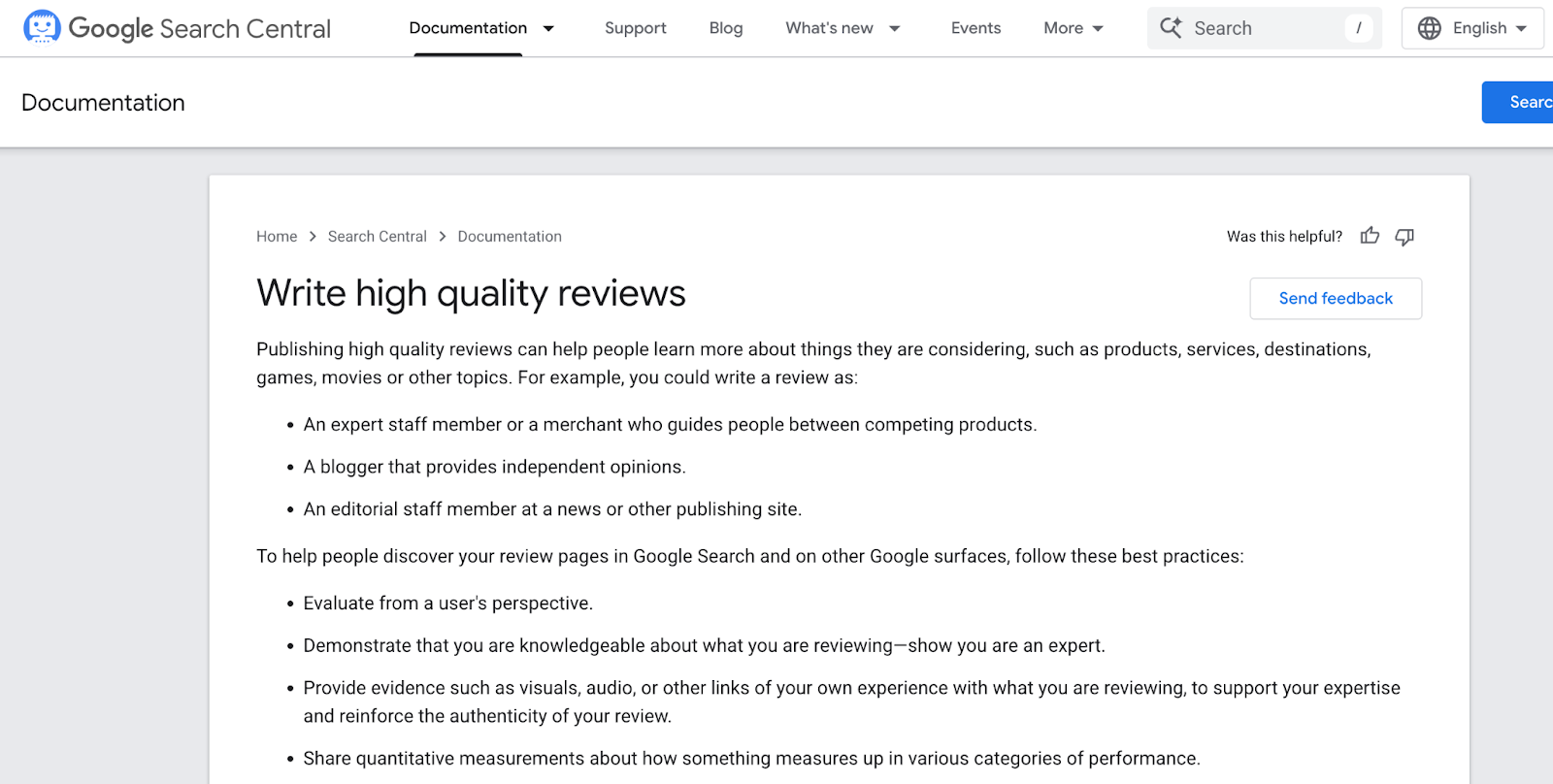
Most self-promotional listicles couldn't meet a single one of these requirements.
Lily Ray put it plainly in her analysis: "How many companies have actually been customers of all the competitors they are reviewing in their listicles?"
The answer, in most cases, was zero. These companies hadn't signed up for competitor products. They hadn't run testing. They hadn't documented methodology. They were ranking themselves #1 based on being the publisher of the article, not based on any comparative evaluation.
That's not a review. That's an advertisement framed as editorial content.
The warning signs were there. Google had published the guidelines. But when the data showed listicles generating AI citations and driving traffic, many companies doubled down anyway.
Google didn't change the rules in January 2026. They enforced rules that had existed since 2021.
The measurement problem: we were guessing
Part of why this caught so many companies off guard comes down to a fundamental problem: throughout 2025, everyone was chasing AI citations without any reliable way to measure them.
Traditional SEO has Search Console. You see impressions, clicks, and positions. You track changes. You make decisions based on data.
But for AI visibility? There was nothing. Companies were building entire strategies around getting cited in ChatGPT, Perplexity, Gemini, and AI Overviews. With no dashboard, no metrics, no way to know what was getting cited or why. "We think this is working" became the standard for measurement.
Then, on February 10, 2026, Bing launched AI Performance in Webmaster Tools, the first official dashboard from a major platform showing AI citation data and it tracks:
- Total citations across Copilot and Bing AI summaries
- Average cited pages per day
- Grounding queries that triggered your citations
- Page-level activity showing which URLs get cited most
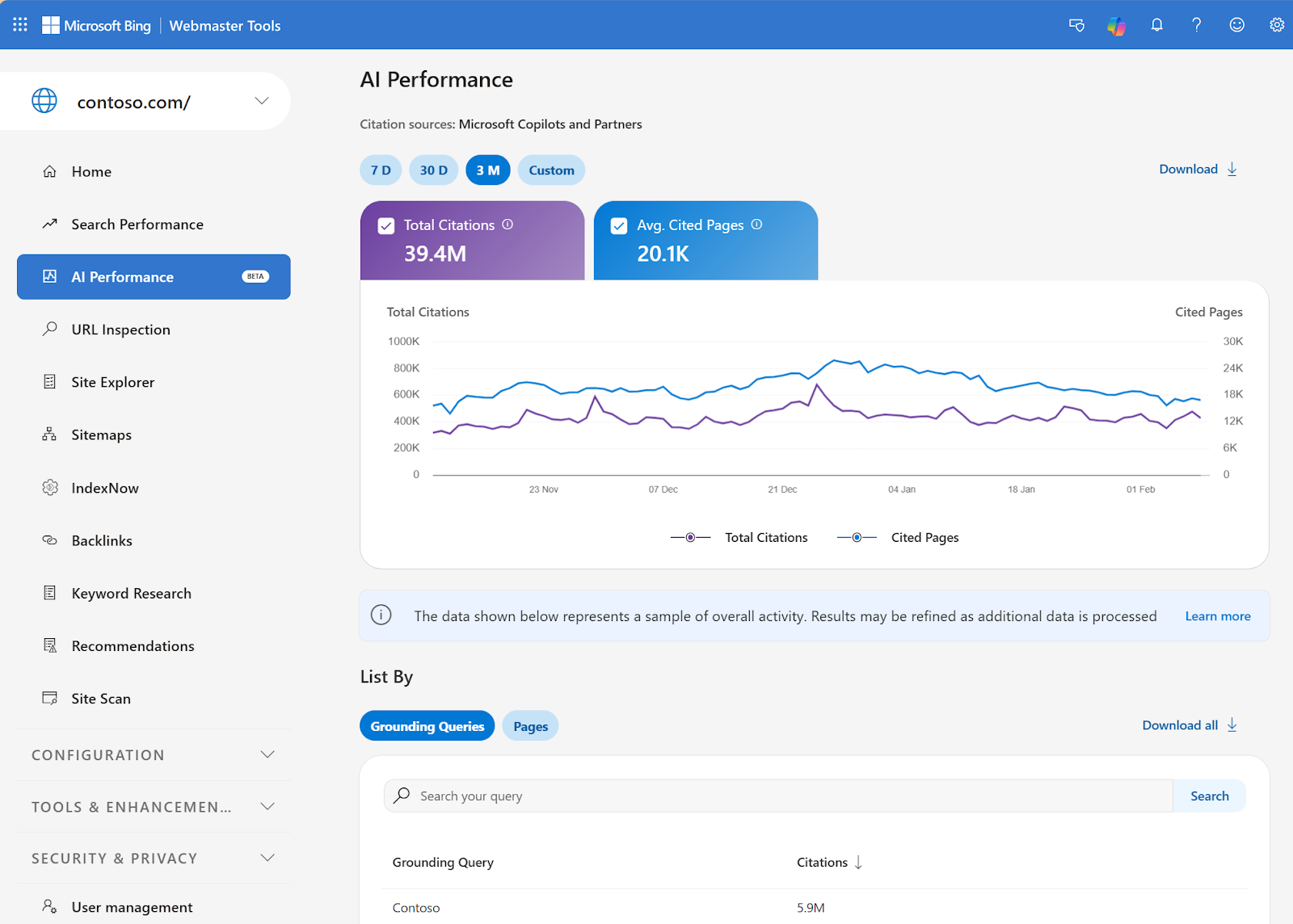
It's a real step forward. But it only covers Microsoft's ecosystem. There's no official dashboard for ChatGPT, Perplexity, Gemini, or Claude. If you want to understand how your brand is showing up across all the places AI search actually happens, you need a third-party tool.
That's the gap ZeroRank was built for. It pulls together your AI visibility across ChatGPT, Perplexity, Gemini, and Claude in one place. Simply showing not just whether you're cited, but how you're characterized, how you compare to competitors, and where they appear in prompts where you don't.
That measurement gap is part of why January 2026 hit so hard. By the time visibility drops showed up in traffic reports, the damage was already done.
What actually works now: 4 listicle strategies
So what should you actually do?
Here's what Google and Bing explicitly say works in their official documentation, translated into actionable strategies you can implement today.
Strategy 1: prove you actually tested it
Here's the core issue with most self-promotional listicles: they describe products without proving anyone actually used them.
In 2022, Google added "Experience" to its E-E-A-T framework specifically to address review and comparison content. The question they ask is simple but revealing:
"Does content also demonstrate that it was produced with some degree of experience, such as with actual use of a product?"
And for Google product reviews specifically, they're explicit about what "experience" looks like in practice:
"It can build trust with readers when they understand the number of products that were tested, what the test results were, and how the tests were conducted, all accompanied by evidence of the work involved, such as photographs."
Evidence. Test results. Methodology. Screenshots. These aren't suggestions, they're what Google's Quality Raters are trained to look for when evaluating whether review content meets their standards.
The gap between what most listicles provide and what Google actually requires looks like this:
What Most Listicles Do | What Google Actually Requires |
"Tool A is easy to use" | Screenshot showing the interface during actual use |
"We compared 7 tools" | Documentation of when and how each tool was tested |
"Priced at $199/month" | "We tested the Pro plan at $199/month from Jan 15-30" |
"Tool A ranks #1" | Scoring framework showing exactly how you evaluated each tool |
"Cons: limited features" | Specific features you tried and couldn't find during testing |
What this means practically: every comparison article needs a real "How We Tested" section, not a paragraph placed at the bottom, but a clear methodology near the top explaining your evaluation criteria, which plans you tested, how long, and what you measured.
And being honest about limitations doesn't weaken your article. "We focused on small business use cases and didn't test enterprise features" is exactly what a real reviewer would say. It signals credibility, not incompetence. Google's Quality Raters are specifically trained to trust content that acknowledges its own scope.
Strategy 2: structure content so AI can extract it
Think about how AI actually works when it generates an answer. It's scanning your page looking for clear, extractable information, specific facts, comparisons, criteria, and conclusions. If your content is hidden inside dense paragraphs or labeled with generic headings, it gets ignored.
Bing's AI Performance announcement addressed this directly. Their official guidance tells publishers to "spot opportunities to improve clarity, structure, or completeness on pages that are indexed but less frequently cited."
And specifically: "Clear headings, tables, and FAQ sections help surface key information and make content easier for AI systems to reference accurately" and "examples, data, and cited sources help build trust when content is reused in AI-generated answers."
This sounds obvious, but most comparison content fails here in a very specific way. The information exists. It's just not organized for extraction.
The difference usually comes down to headings. A heading like "Our Analysis" tells AI nothing about what's inside. A heading like "Performance Comparison: Load Speed Test Results" tells AI exactly what that section contains and makes it far more likely to be cited when someone asks about performance.
Here are a few heading examples of before and after:
Unclear Headings (Hard for AI to Parse) | Descriptive Headings (Easy for AI to Extract) |
"Our Analysis" | "Performance Comparison: Load Speed Results" |
"The Results" | "Who Each Product Works Best For" |
"Pros and Cons" | "Where Tool A Falls Short for Enterprise Teams" |
"Conclusion" | "Pricing Breakdown: What You Actually Pay Per User" |
"Overview" | "How We Tested: Methodology and Evaluation Criteria" |
Also, the structure of your data matters. Don't wrap important comparisons in paragraph form. A sentence like "Tool A was faster than Tool B in our testing" is harder for AI to extract and quote than a table showing actual measurements.
Strategy 3: track your AI visibility
If the measurement problem was part of what caused this crackdown to catch everyone off guard, then tracking is how you make sure you're not caught off guard again.
Start with Bing's AI Performance dashboard in Webmaster Tools. It shows which of your pages are getting cited, what grounding queries triggered those citations, and how volume trends over time. Worth setting up if you haven't already.
The limitation is that it only covers Microsoft's ecosystem: Copilot and Bing AI summaries. ChatGPT with 800M weekly users, Perplexity, Gemini, Claude, and Google AI Overviews (the platforms driving the majority of AI search traffic) have no official dashboards.
So if you want visibility there, you need a third-party tool.
We built ZeroRank specifically to fill that gap. Here's what that actually looks like in practice.
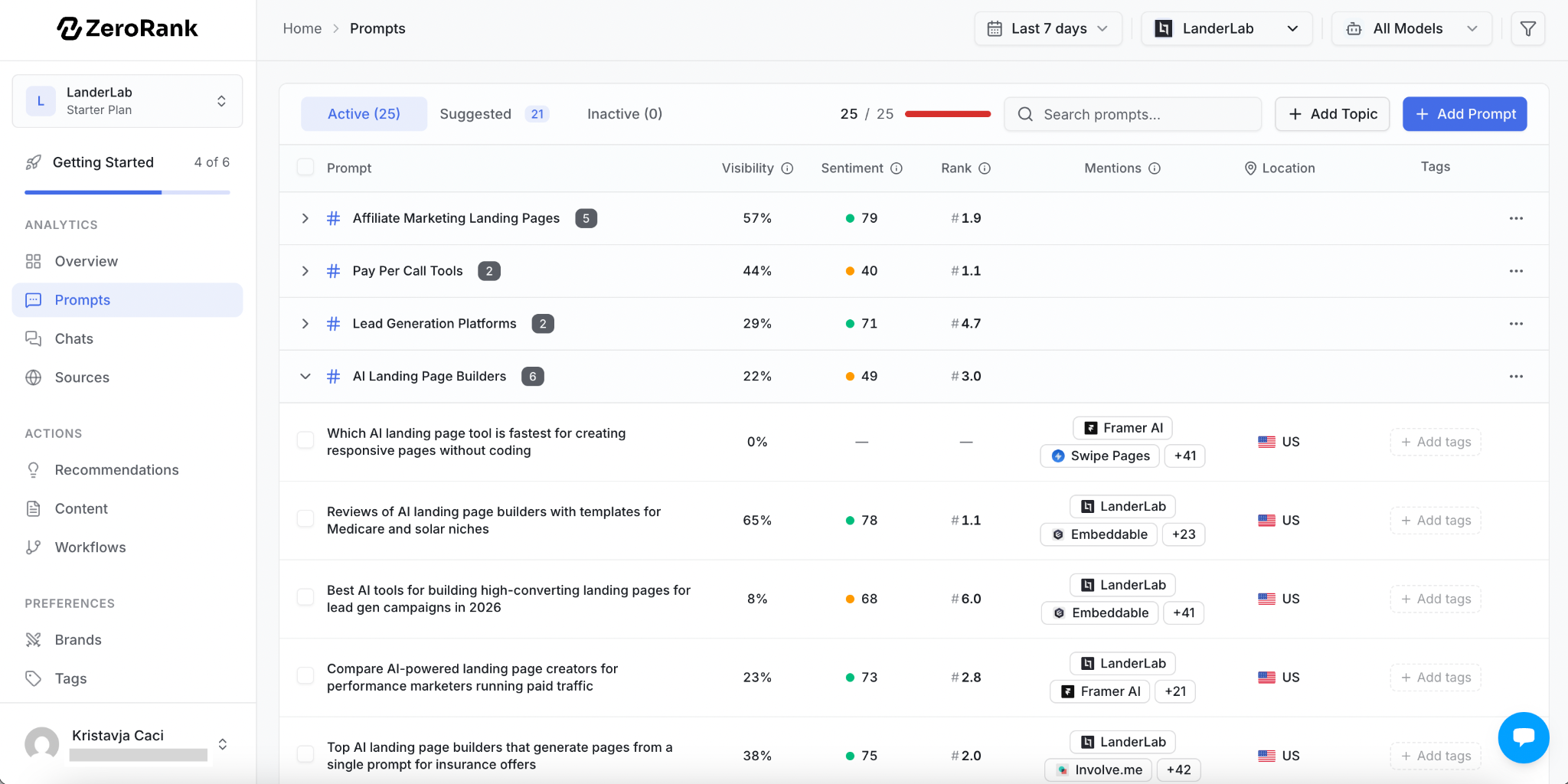
You add your website, and within minutes ZeroRank automatically identifies and tracks all your competitors. The dashboard shows visibility percentage, ranking position, sentiment, and how often each brand is mentioned across real AI conversations, filterable by model, prompt, or competitor.
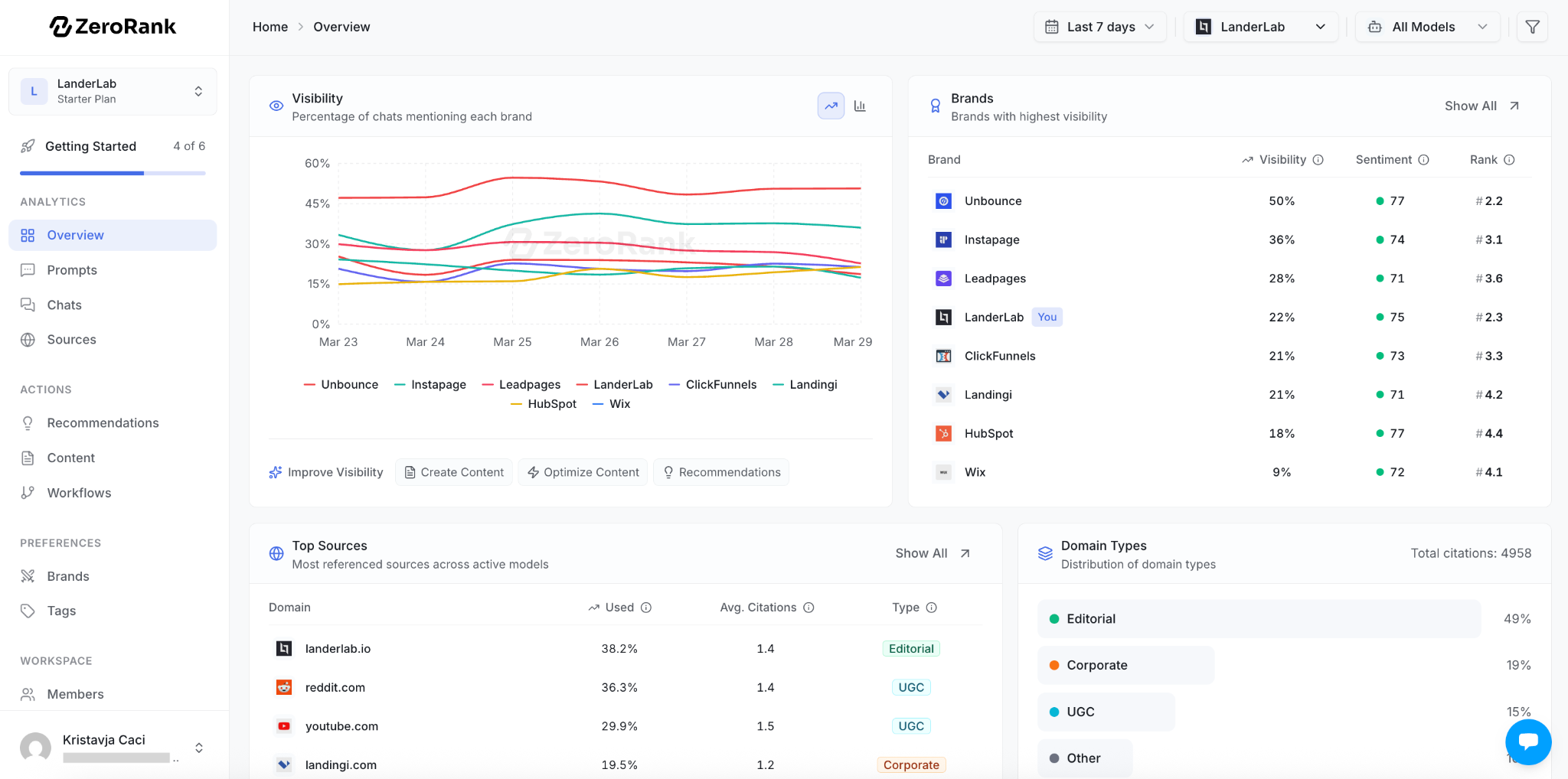
You can see the specific sources where AI cites your competitors but not your brand, showing you exactly which content is missing you from the conversation
From there, you can use the built-in AI Content Generation to create content targeting those gaps or AI Content Optimization to improve existing pages so they get cited more often.
The Content Generation comes with built-in templates so you don’t have to start from scratch.
Everything updates daily, so changes in AI behavior show up quickly rather than weeks later.
For larger teams, automated Workflows let you build repeatable processes for content creation, review, and publishing tied directly to visibility data.
Regardless of which AI search visibility tools you use, these are the four things worth tracking:
- Citation rate: How often are you mentioned, and is it trending up or down?
- Characterization: What language does AI use to describe you? Is it accurate?
- Context: What questions trigger citations? What other brands appear alongside you?
- Gaps: Where do competitors show up that you don't, and why?
The goal is understanding what's driving them so you can make content decisions based on data instead of assumptions.
Strategy 4: build authority that can be verified
Google's E-E-A-T guidelines ask: "Consider the extent to which the content is authoritative, such as through citations or links."
Authority isn't claimed. It's earned when other people cite you.
The fastest way to become citable is to publish something nobody else has. Not a better-written version of the same comparison. Survey actual users. Test edge cases that others skip. Publish the raw data. "We Tested 7 CRMs with 50,000-Contact Databases: Here's What Broke Under Load" gets cited. "Best CRM Tools 2026" doesn't.
And when you do update existing content, make it a real update. Google's Helpful Content guidelines are direct about this: content should exist to serve the genuine interests of visitors, not to attract search engines.
A real update means re-testing. New pricing. New features. Products that launched or shut down since your last review. If nothing changed, say so, but if things did change, show the work.
Adding "Last edited with new date" at the top of an article signals something simple but powerful: that a real person is maintaining this, not a bot.
The bottom line about the listicle crackdown
This wasn't about listicles. It was about legitimacy.
Google's Product Review standards have existed since 2021. The rules didn't change in January 2026 (the enforcement did). And for companies that built strategies around self-promotional comparison content without real testing behind it, that distinction arrived as a 30-50% visibility drop.
The format still works. Comparative content still dominates AI citations. But structure without value doesn't anymore.
Document your testing. Be transparent about your methodology. Make real updates. Build content that could stand up to scrutiny, because increasingly, it will.
And track what's actually happening to your visibility across platforms. Bing's new dashboard is a start. Third-party tools like ZeroRank exist specifically to cover the rest. Showing exactly where and how your brand appears across ChatGPT, Perplexity, Gemini, Google AI Mode, Google AI Overviews, Bing Co-pilot, and Grok answers.
SEO shortcuts create technical debt. The brands that come out ahead are the ones building authority that both algorithms and humans can verify.
That's always been the standard. It's just being enforced now.

